
Apach Kafka를 사용하기에 앞서 데이터 파이프라인에 대해 간단하게 알아보고자 포스팅을 작성합니다.
그랩의 IT 뉴스레터를 참고하여 작성하였습니다.
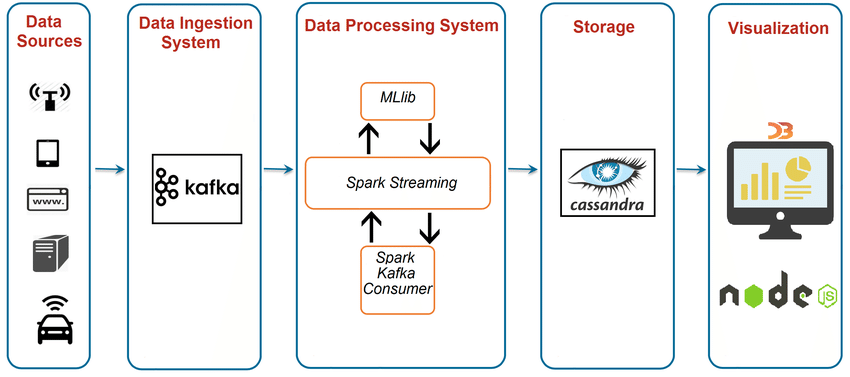
데이터 파이프라인 개요
- 데이터 생성
- 데이터 수집
- 데이터 가공 후 저장 (ETL)
- 데이터 분석 및 시각화 (BI)
데이터 생성
데이터의 종류는 크게 두 가지로 나뉩니다.
- 서비스 데이터
- ex) 상품 정보, 고객 정보
- 로그 데이터
- ex) 클릭, 스크롤, 머무르기 같은 이벤트
- 클라이언트 로그
- 유저가 서비스를 사용하면서 생성되는 로그
- 서버 로그
- 백엔드 서버에서 발생하는 로그
IT 회사에서 다루는 데이터는 로그 데이터가 대부분을 차지합니다.
데이터 수집
수집된 데이터들은 바로 데이터베이스에 저장되지 않고 수집서버 (Kafka, Kinesis, … )에 들어갑니다. 수집 서버에서는 데이터를 데이터베이스에 저장하거나 데이터를 추가로 가공하는 서버에 전달합니다.
데이터 가공
데이터 가공은 ETL이라는 프로세스를 통해 이루어집니다.
ETL
- Extract
- 흩어져 있는 데이터 소스로부터 데이터를 추출해 가져옵니다.
- Transform
- 데이터를 가공하는 작업입니다.
- 비정형 데이터를 정형 데이터로 가공합니다.
- Load
- 가공한 데이터를 데이터베이스에 최종적으로 저장합니다.
데이터 시각화
데이터 시각화 템플릿과 환경을 제공해주는 도구를 Buisness Intelligence(BI)이라고 합니다.