
이 포스팅은 cloudkarfka의 article을 참고하여 작성하였습니다.
1. Kafka란?
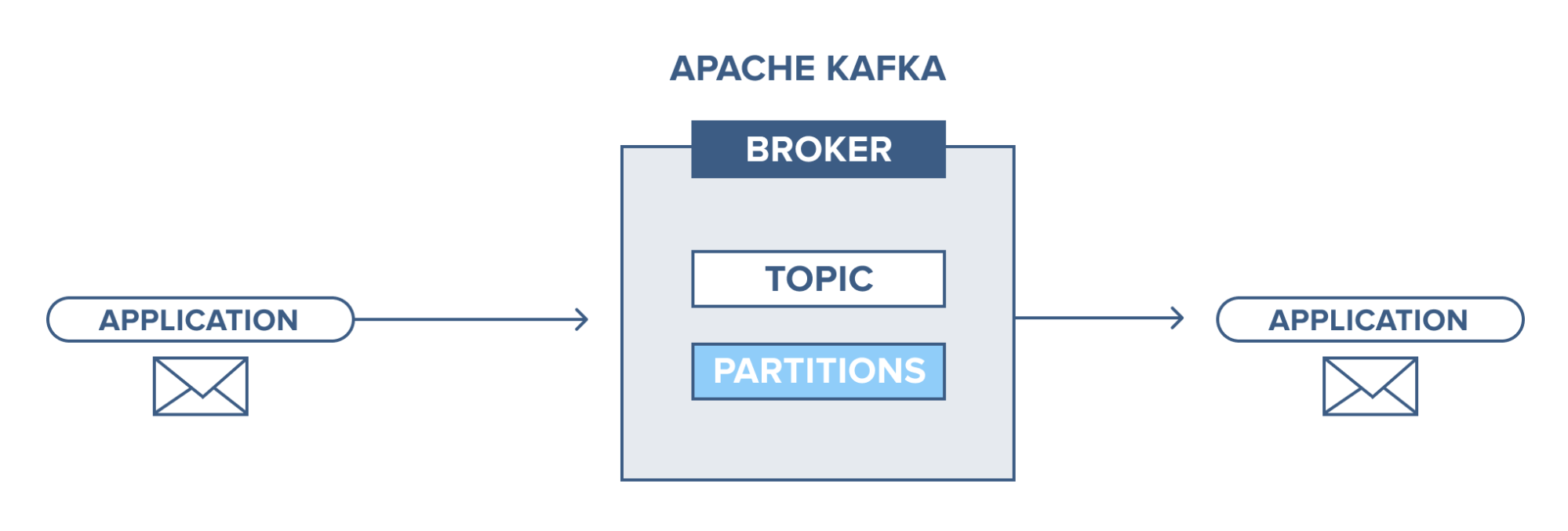
Kafka는 publish-subscribe모델의 메시지 큐 시스템입니다.
pub-sub 모델
메시지를 생산해내는 publisher와 메시지를 수신하는 receiver가 있다고 가정해보겠습니다. pub-sub모델은 publisher가 receiver에게 메시지를 직접 전달해주지 않고 브로커에게 전달합니다. 브로커는 전달받은 메시지를 알맞은 topic에 따라 분류하여 카테고리화 합니다. receiver는 원하는 메시지가 있는 topic을 구독(subscribe)하여 브로커로부터 메시지를 받을 수 있습니다.
2. 관련 용어 정리
2.1 데이터의 단위와 데이터가 쓰여지는 공간
Record
Producer와 Consumer가 데이터를 주고 받는 단위입니다. event와 message 등이 record로 사용될 수 있습니다. record는 key-value 형태를 가져야 하며 timestamp, header 와 같은 메타데이터를 포함할 수 있습니다.
Topic
Topic은 record가 저장되는 공간입니다. Topic은 파일 시스템의 폴더와 유사하며, record는 폴더 안의 파일과 유사합니다.
Partition
하나의 Topic은 다시 여러 개의 Partition으로 나뉩니다. 따라서 record가 실질적으로 쓰여지는 공간은 topic 안에 존재하는 하나의 partition이라고 볼 수 있습니다. 하나의 partition에는 여러 개의 record가 존재하기 때문에 record별로 offset을 부여해 관리합니다.
이를 통해 여러 소비자가 하나의 topic으로부터 메시지를 병렬적으로 읽을 수 있습니다.
2.2 Kafka 핵심 구성요소
Brocker와 Zookeeper
Kafka 클러스터는 Kafka를 실행하는 하나 이상의 서버로 구성됩니다. brocker는 바로 이 서버를 의미하며 각 클러스터에는 한 개 이상의 brocker가 존재합니다. brocker는 Client로부터 오는 모든 요청을 처리해 Kafka 클러스터에 데이터를 복제해둡니다. 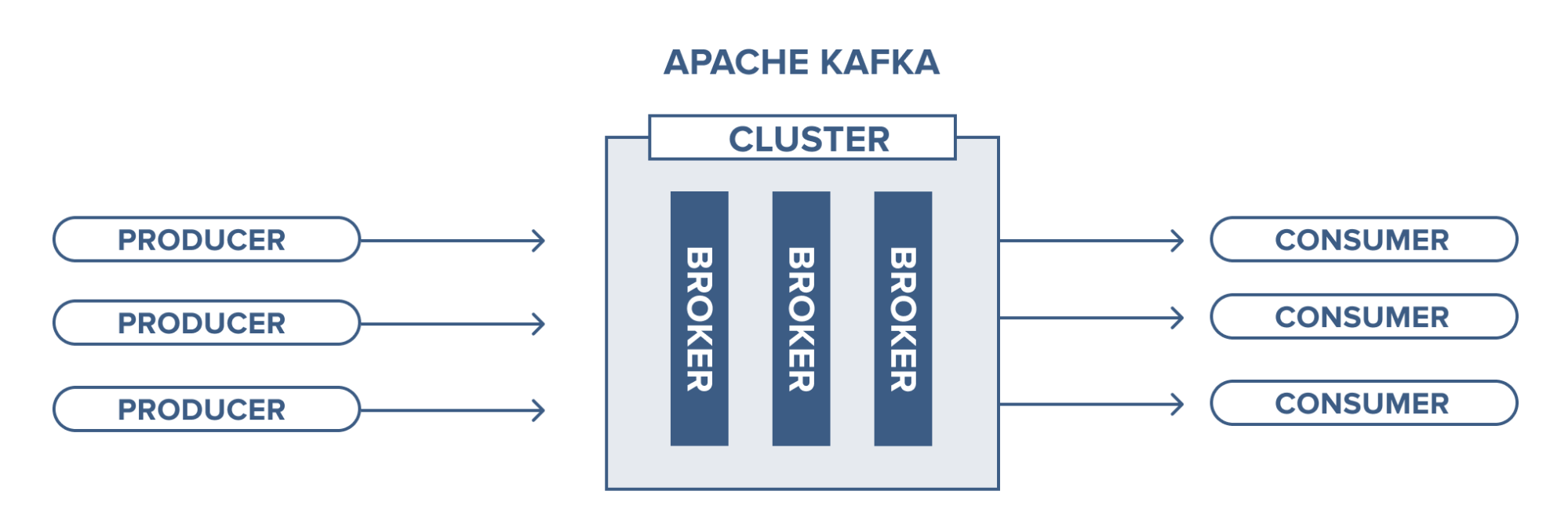
zookeeper는 클러스트의 브로커를 관리합니다. 따라서 Kafka를 실행하기 위해서는 zookeeper를 반드시 실행해야 합니다.
Producer
producer는 메시지를 생산해내고 broker를 통해 Kafka topic에 record를 저장합니다. record의 key를 통해 record가 저장되는 partition이 지정되고 이를 통해 원하는 partition에 record를 저장할 수 있습니다.
Consumer
consumer는 특정 offset에서 시작하여 메시지를 읽어들입니다. 따라서 Consumer가 나갔다가 들어와도 offset을 통해 이전에 읽어들였던 위치부터 계속 읽을 수 있습니다. Kafka의 partition은 오로지 하나의 consumer의 접근만을 허용합니다.
Consumer Group
Kafka는 동일한 topic을 읽는 소비자들을 묶어 그룹으로 관리합니다. consumer group은 topic에 대응되고 consumer group에 속한 consumer는 해당 topic의 partition에 대응됩니다. 따라서 partition의 개수와 consumer 수의 적절한 설정이 필요합니다.
3. Kafka에서의 Record 흐름
다음은 broker가 record를 어떻게 전달받고 저장하는지 알아보겠습니다.
아래 그림과 같이 세 개의 topic을 가진 한 브로커를 예로 들어보겠습니다. 세 개의 topic은 각각 8개의 partition을 갖고 있습니다. 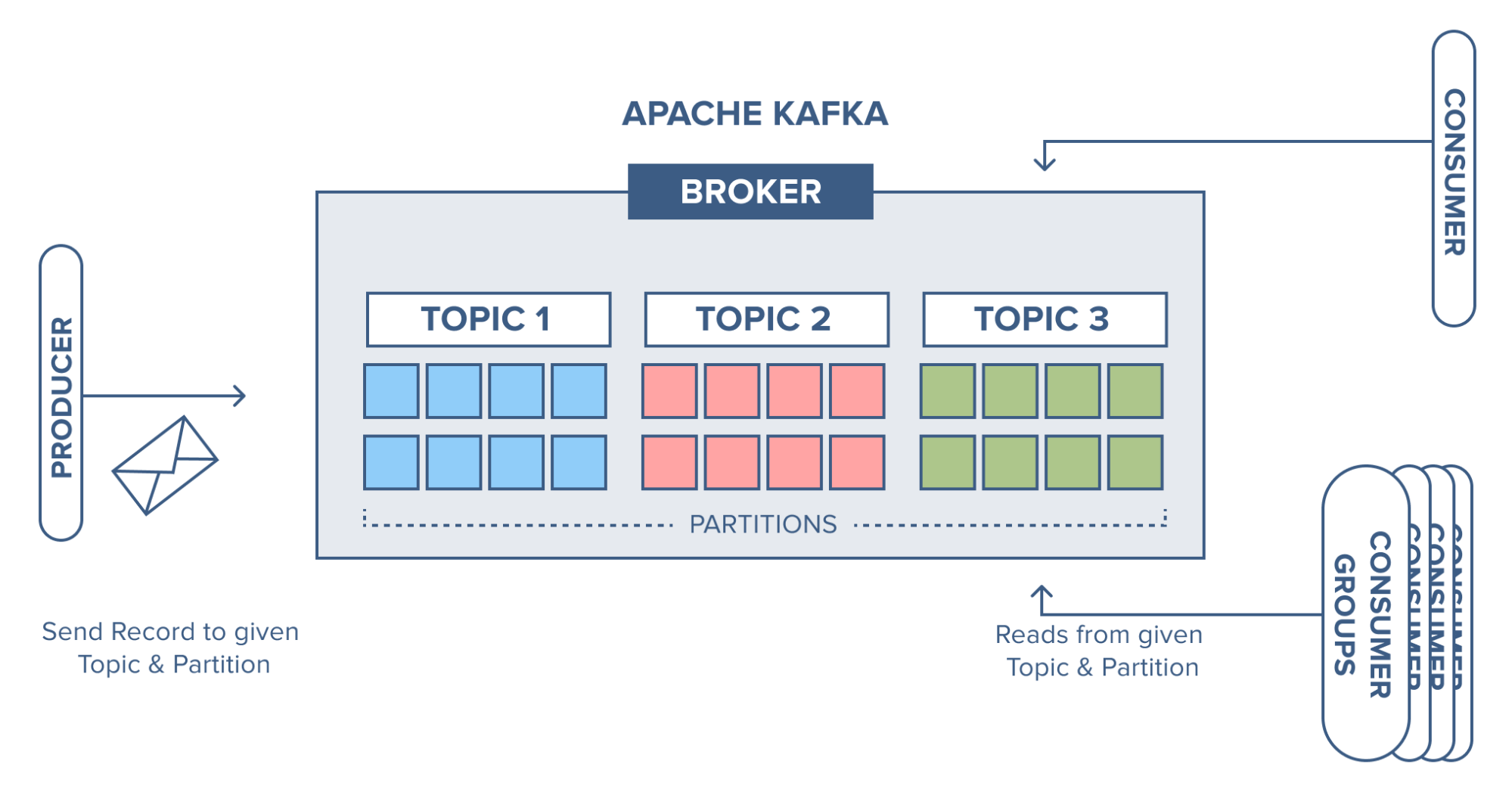 producer는
producer는 topic 1의 첫 번째 partition에 record를 전송합니다. 해당 partition은 비어있었으므로 이 partition의 offset은 0입니다. 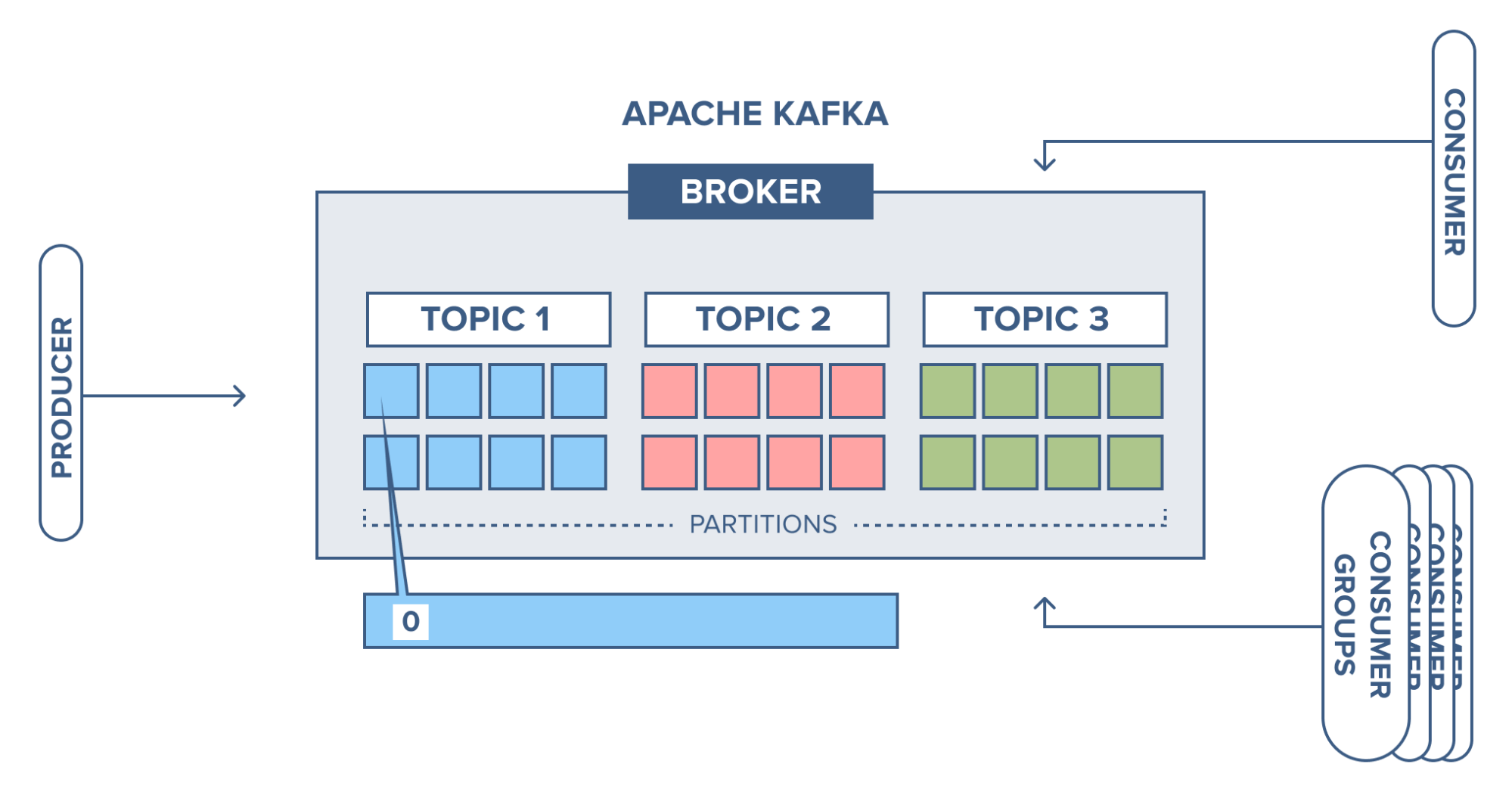
다음 record도 같은 partition에 추가된다면 offset은 1에서 더 증가하게 되고 다음 record는 offset 2에서 계속됩니다. 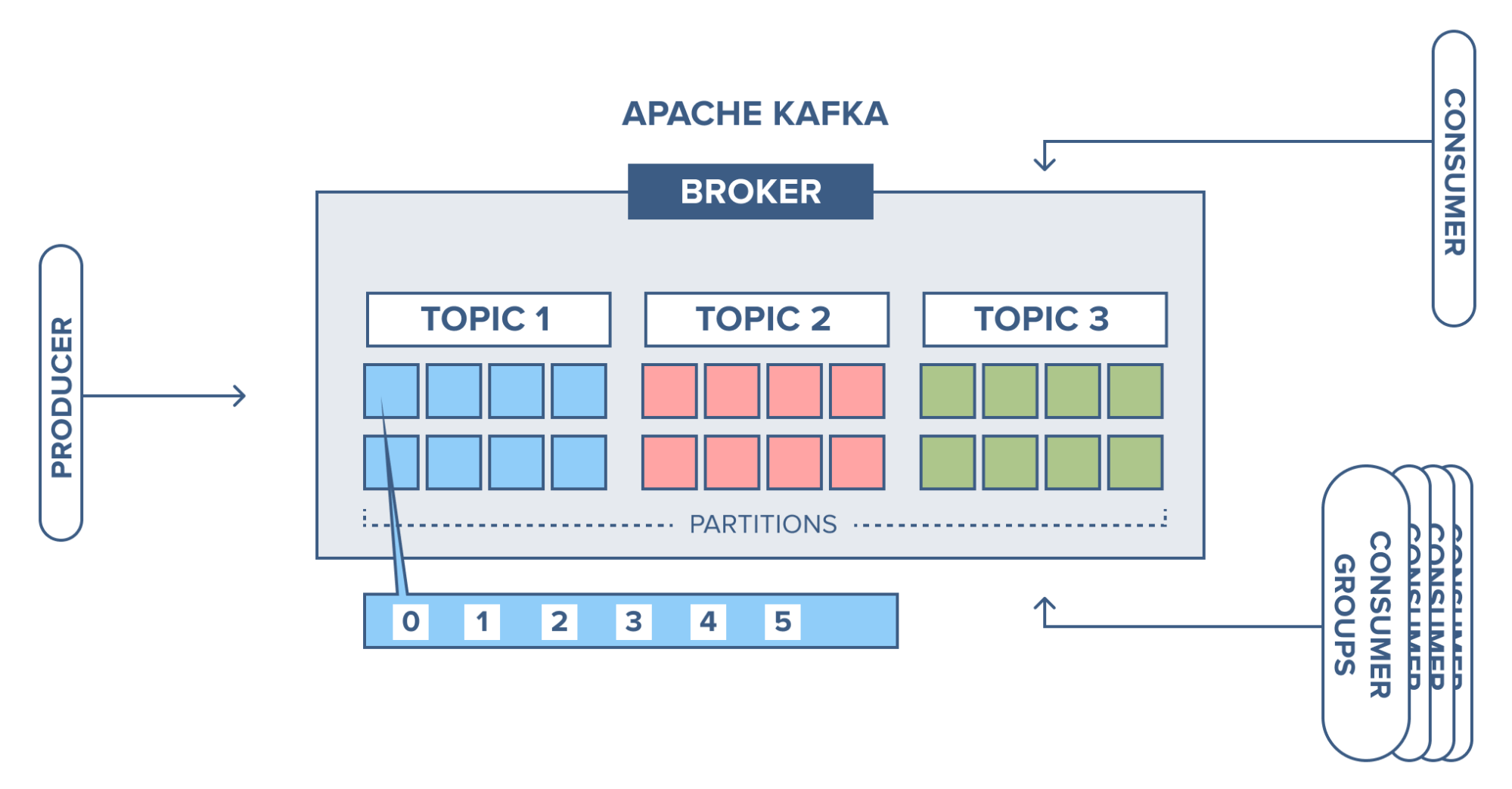
4. Apache Kafka 사용 예시
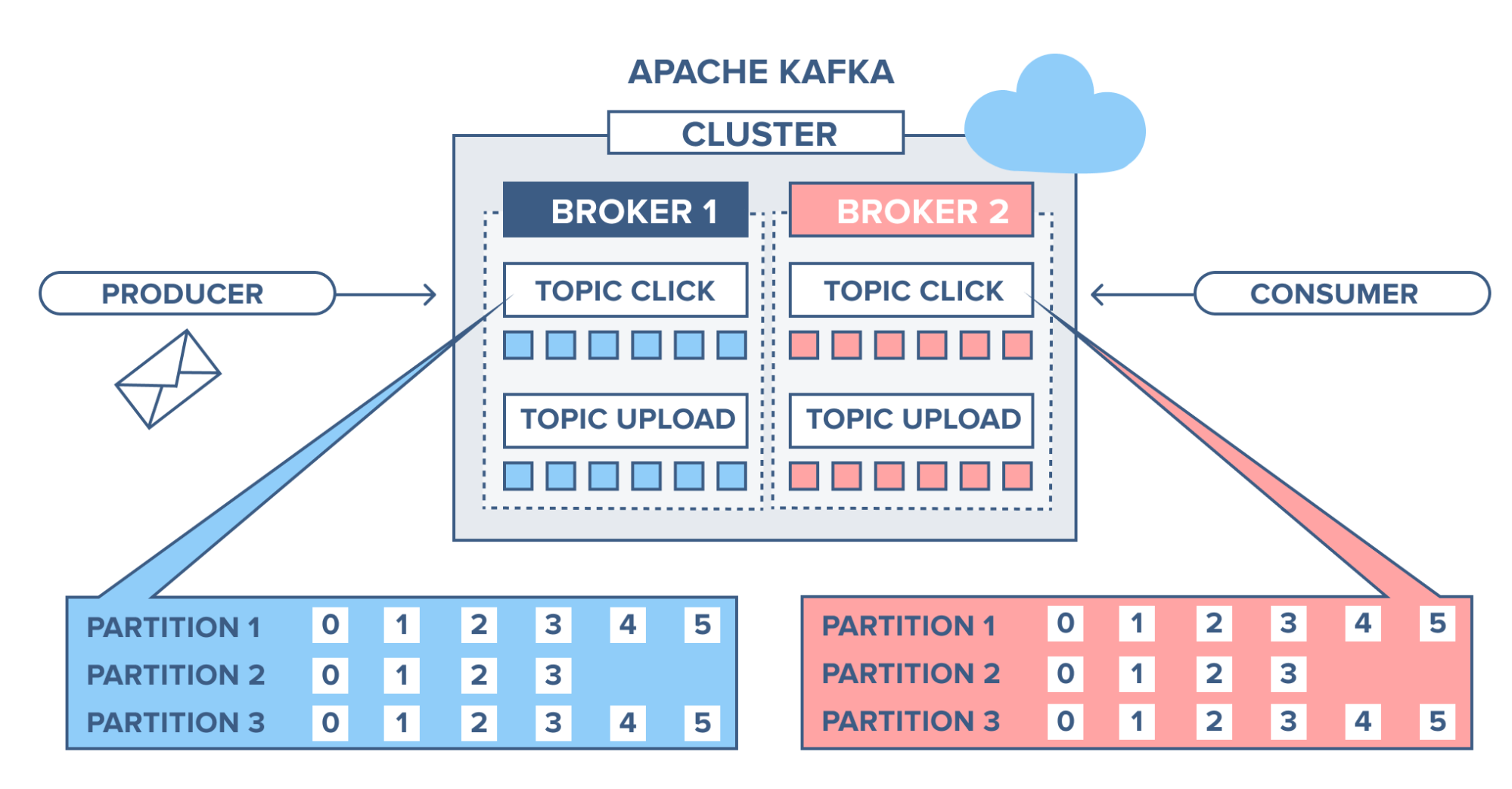
Website Activity Tracking
원래 카프카는 사용자의 활동을 추적하는 파이프라인을 실시간 pub-sub 모델로 재구성하는 것이었습니다. 즉, 사이트 활동(페이지 조회, 검색 등 사용자가 취할 수 있는 활동)은 활동 타입마다 그에 해당하는 하나의 topic으로 발행됩니다.
- user-id가 0인 사용자가 웹사이트의 버튼을 클릭합니다.
- 웹 애플리케이션은
Clicktopic에 record를 저장합니다. - 레코드가 커밋 로그에 추가되고 메시지 offset이 증가합니다.
- 소비자는
Clicktopic에서 메시지를 가져와 실시간으로 모니터링 사용량을 표시하거나 offset을 당겨서 이전에 소비된 메시지를 다시 읽을 수 있습니다.![image]()
Message queue
카프카는 RabbitMQ와 같은 기존의 메시지 브로커들을 대체할 수 있습니다. 카프카의 메시징은 프로세스를 분리하고 확장성이 뛰어난 시스템을 만듭니다. 하나의 대규모 애플리케이션을 구축하는 대신 애플리케이션을 나누고 메시지를 통해 비동기적으로 통신을 하는 것이 가능합니다. 이를 통해 각각의 애플리케이션이 독립성을 갖게되어 서로 다른 언어로 작성되거나 분리된 개발팀에서 관리가 가능합니다.
Kafka는 다른 메시지 시스템과 비교하여 더 높은 처리량을 보이고 파티셔닝/복제 및 내결함성이 내장되어 있어 대규모 메시지 처리 애플리케이션에 적합합니다.